
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Absolute
- AGI
- ai
- AI agents
- AI engineer
- AI researcher
- ajax
- algorithm
- Algorithms
- aliases
- Array 객체
- ASI
- bayes' theorem
- Bit
- Blur
- BOM
- bootstrap
- canva
- challenges
- ChatGPT
- Today
- In Total
A Joyful AI Research Journey🌳😊
[5] 241105 Streamlit [Goorm All-In-One Pass! AI Project Master - 4th Session, Day 5] 본문
[5] 241105 Streamlit [Goorm All-In-One Pass! AI Project Master - 4th Session, Day 5]
yjyuwisely 2024. 11. 5. 09:03241104 Mon 4th class
오늘 배운 것 중 기억할 것을 정리했다.
OpenAI도 선하게 시작함
복습은 필수다.
Steamlit 기획서 쓰는 것 보다 더 빠를 수 있다.
https://rowan-sail-868.notion.site/11b7d480b59380e69285f6f7b9ea7359
최종 프로젝트 내용 | Notion
10월 26일 발표 순서
rowan-sail-868.notion.site
아나콘다 - 300개 이상 프로그램 설치해 준 것.
시각화, 데이터 수집
가상 개발 환경
https://rowan-sail-868.notion.site/streamlit-app-b170701a174b45e88a54882a79d712af
streamlit app 기본 시작하기 | Notion
기본 환경 만들어 보기
rowan-sail-868.notion.site
streamlit run streamlit_01.py
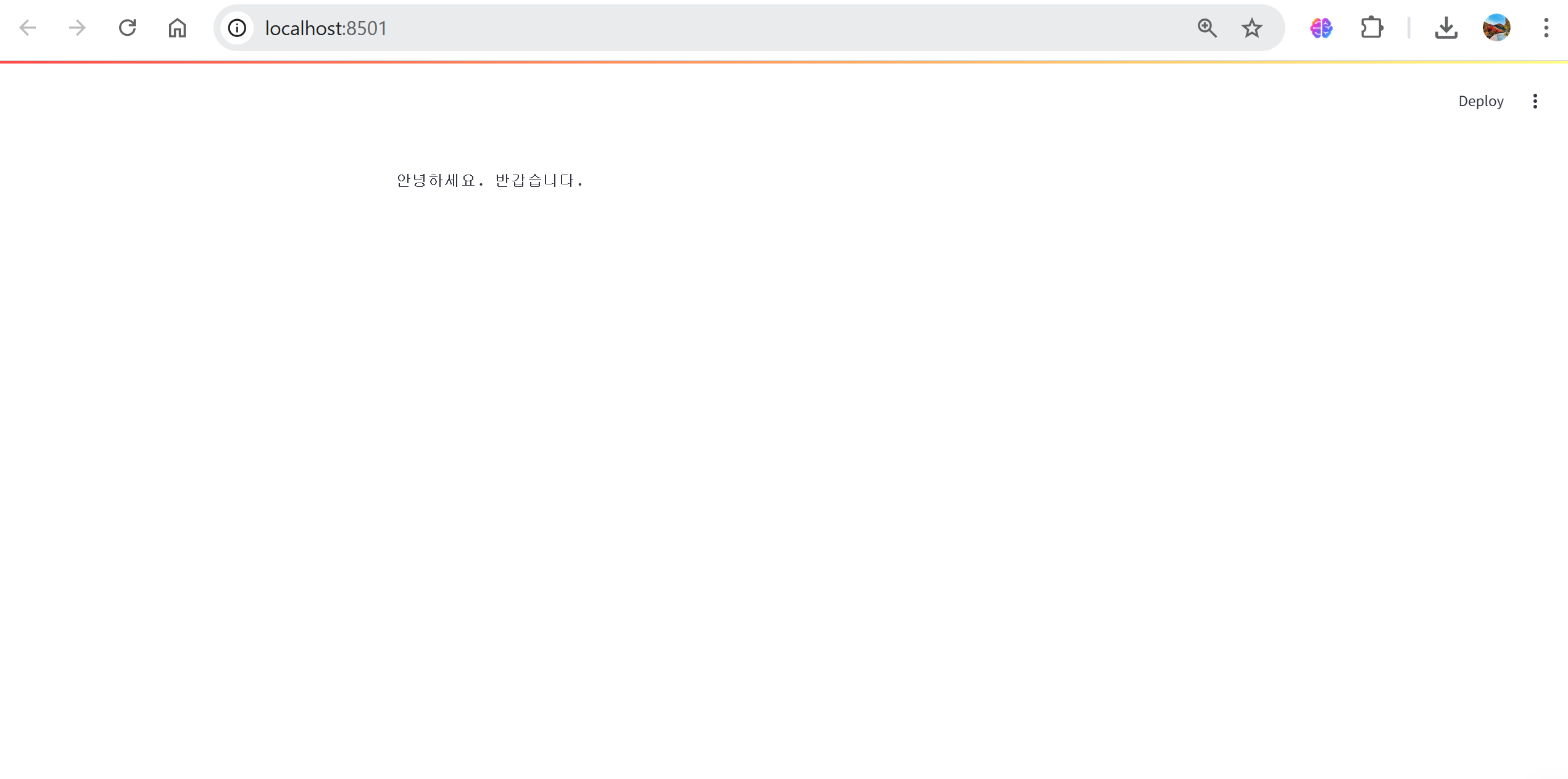
1-7 실습 1 - 그래프 그려보기
1-7 실습 2 - 버튼 동작 구현해 보기
https://rowan-sail-868.notion.site/streamlit-app-7fe64728b21049d58dcf46a7a19c60a0?pvs=74
streamlit app 생성해보기 | Notion
Notion 팁: 페이지를 생성할 때는 명확한 제목과 관련된 내용이 필요합니다. 인증된 정보를 사용하고, 페이지 주제를 확실히 하고, 주요 이슈에 대한 의견을 공유하세요.
rowan-sail-868.notion.site
Open GitHub Codespaces to immediately edit this app in your browser. 체크하면 나오는 화면
https://docs.streamlit.io/get-started/tutorials/create-an-app
Streamlit Docs
Join the community Streamlit is more than just a way to make data apps, it's also a community of creators that share their apps and ideas and help each other make their work better. Please come join us on the community forum. We love to hear your questions
docs.streamlit.io
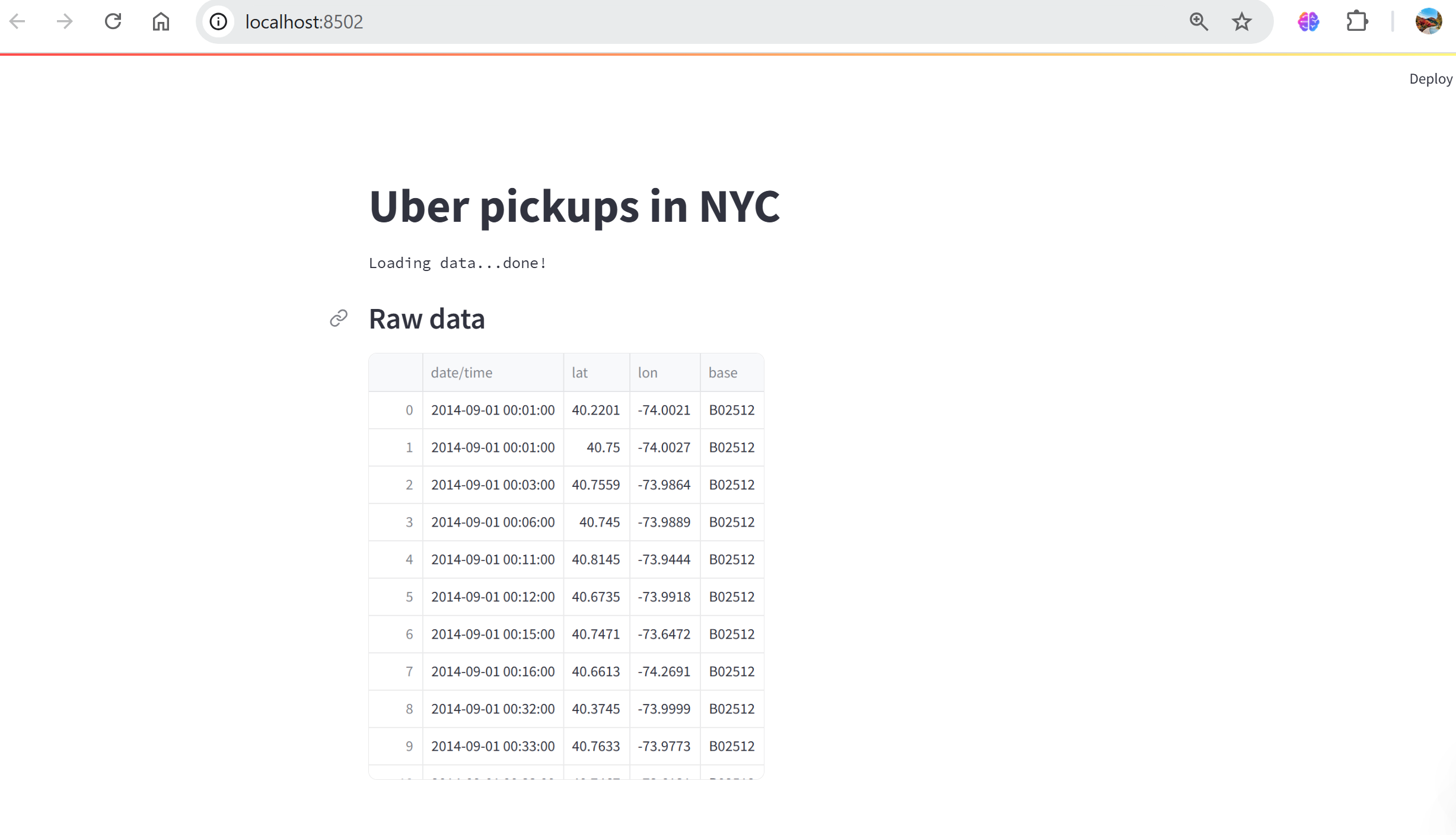
코드)
import streamlit as st
import pandas as pd
import numpy as np
st.title('Uber pickups in NYC')
DATE_COLUMN = 'date/time'
DATA_URL = ('https://s3-us-west-2.amazonaws.com/'
'streamlit-demo-data/uber-raw-data-sep14.csv.gz')
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True) #Pandas library
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
# Create a text element and let the reader know the data is loading.
data_load_state = st.text('Loading data...')
# Load 10,000 rows of data into the dataframe.
data = load_data(10000)
# Notify the reader that the data was successfully loaded.
data_load_state.text('Loading data...done!')
st.subheader('Raw data')
st.write(data)결과)
히스토그램은 연속형 데이터에 사용되는 반면, 막대 차트는 범주형 또는 명목형 데이터에 사용
도수분포표 -> 히스토그램으로 표현
도수분포표를 시각화할 때 히스토그램이 흔히 사용
https://blog.naver.com/ssunny1m/222164133080
[간호관리학 /통제] 간호 질 관리 분석도구 : 히스토그램(histogram) vs 막대그래프
함께하니가 알아본 '간호질 관리 분석도구' 안녕하세요? 함께하니 입니다. 이번 시간에는 간호 ...
blog.naver.com
https://leeezxxswd.tistory.com/6
도수분포표와 막대그래프, 히스토그램
2020/11/17 - [데이터 분석 입문/기초통계] - 모집단과 통계, 척도 모집단과 통계, 척도 2020/11/16 - [데이터 분석 입문/기초통계] - 기술통계와 추리통계 1. 중심경향값 : 전체 자료를 대표할 수 있는 수
leeezxxswd.tistory.com
rerun 누르면 나온다.
st.subheader('Number of pickups by hour')
hist_values = np.histogram(
data[DATE_COLUMN].dt.hour, bins=24, range=(0,24))[0]
st.bar_chart(hist_values)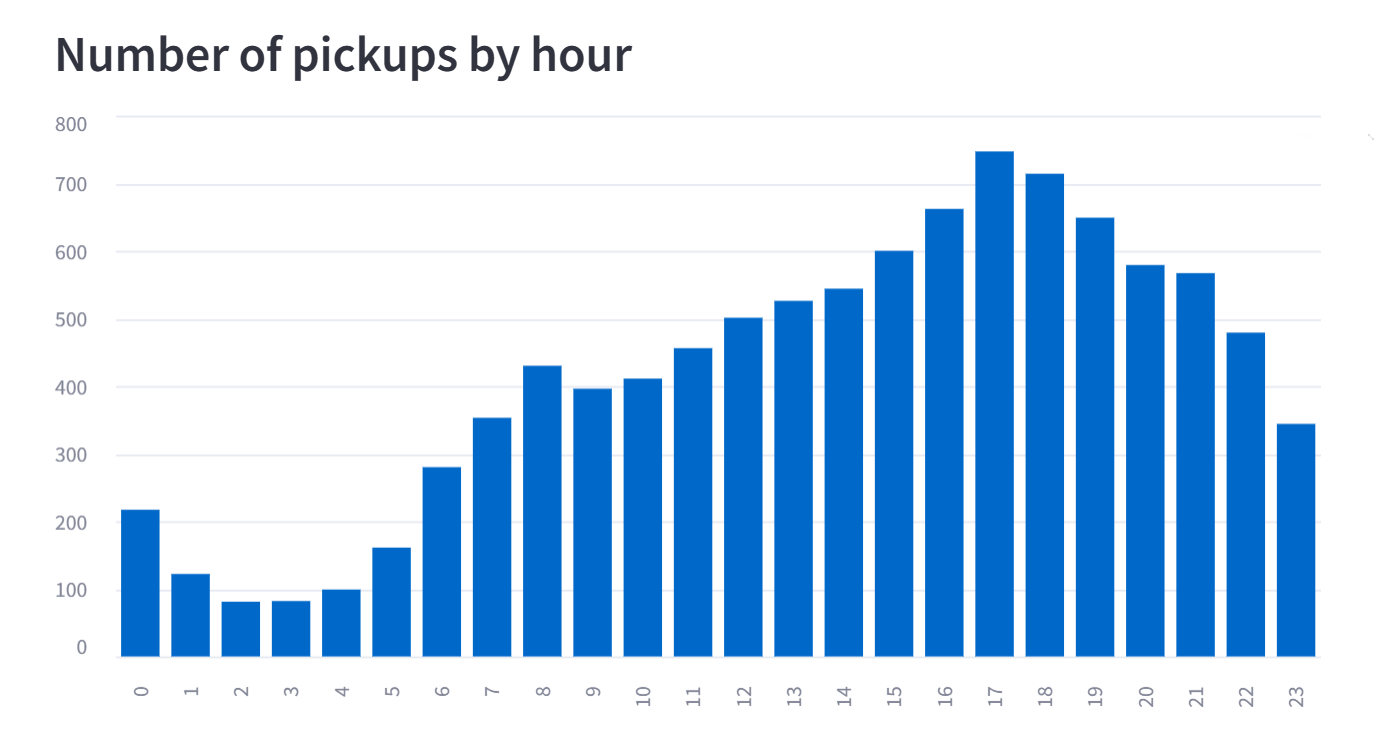
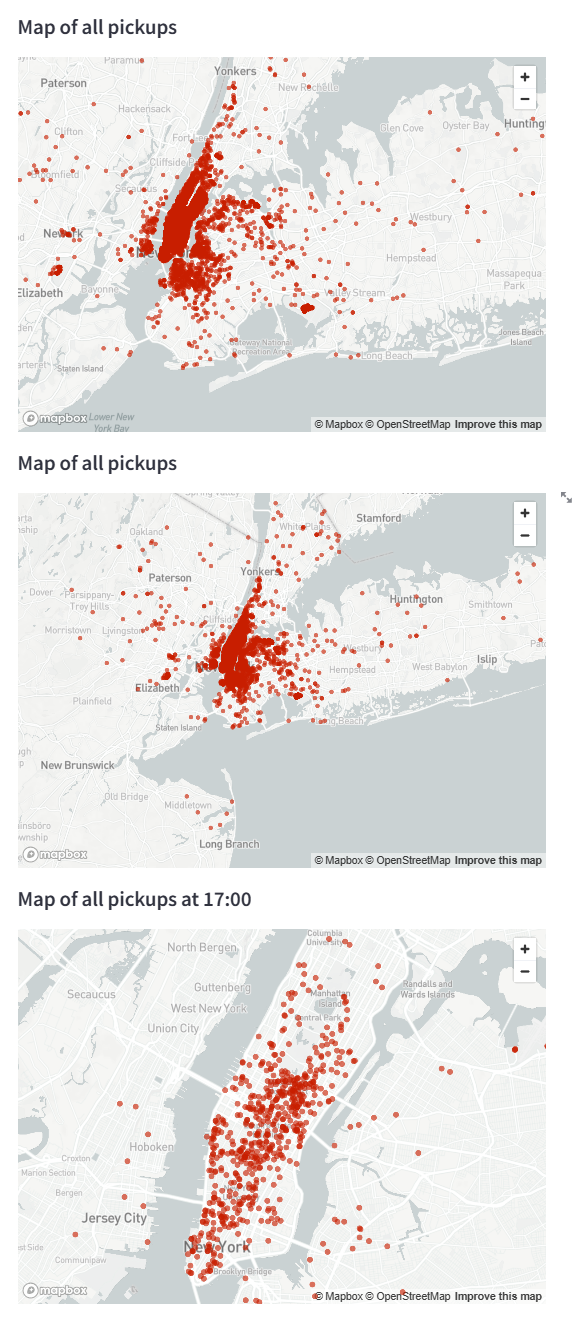
folium
프로토타입: 실제 개발이 나오기 전에 나오는 결과물
코드)
st.subheader('Map of all pickups')
st.map(data)
st.subheader('Map of all pickups')
st.map(data)
hour_to_filter = 17
filtered_data = data[data[DATE_COLUMN].dt.hour == hour_to_filter]
st.subheader(f'Map of all pickups at {hour_to_filter}:00')
st.map(filtered_data)결과)
3-2 다른 데이터 표시해 보기
3-3 다른 데이터 불러와서 시각화 해보기
3-4 [레벨업] chatgpt & claude를 활용한 머신러닝 예측 앱
4-4 [레벨 업 실습 1] 나만의 앱을 만들어서 배포해 보기
[스트림릿] Github로 연동해서 페이지 Deploy하기
Github와 연동해서 App 배포하기.
velog.io



