
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Absolute
- AGI
- ai
- AI agents
- AI engineer
- AI researcher
- ajax
- algorithm
- Algorithms
- aliases
- Array 객체
- ASI
- bayes' theorem
- Bit
- Blur
- BOM
- bootstrap
- canva
- challenges
- ChatGPT
- Today
- In Total
A Joyful AI Research Journey🌳😊
[10] 241112 DL, K-Nearest Neighbor (KNN), Decision Tree [Goorm All-In-One Pass! AI Project Master - 4th Session, Day 10] 본문
[10] 241112 DL, K-Nearest Neighbor (KNN), Decision Tree [Goorm All-In-One Pass! AI Project Master - 4th Session, Day 10]
yjyuwisely 2024. 11. 12. 13:40241112 Tue 10th class
오늘 배운 것 중 기억할 것을 정리했다.
llm pandas 많이 쓴다.
pandas 자동화
이론, 논문을 알아야한다.
통계 3,4학년, 공대 대학원
카이스트 대학원 - 논문, 전문 용어
타이타닉 캐글 초보자
https://www.kaggle.com/competitions/titanic
Titanic - Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
www.kaggle.com
https://rowan-sail-868.notion.site/46295e260bdf4588b6841eabcde0d01c
머신러닝/딥러닝 기본 및 실습 | Notion
Notion 팁: 페이지를 생성할 때는 명확한 제목과 관련된 내용이 필요합니다. 인증된 정보를 사용하고, 페이지 주제를 확실히 하고, 주요 이슈에 대한 의견을 공유하세요.
rowan-sail-868.notion.site
https://ldjwj.github.io/ML_Basic_Class/part03_ml/ch02_01_01B_knn_code_pratice_2205.html
ch02_01_01_knn_code_pratice
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
ldjwj.github.io
http://localhost:8888/notebooks/Documents%2FICT4th%2FML_Code%2F20241112_Lib01_Pandas.ipynb
01 데이터 준비
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as npdat = pd.read_csv("./data/titanic/train.csv")
dat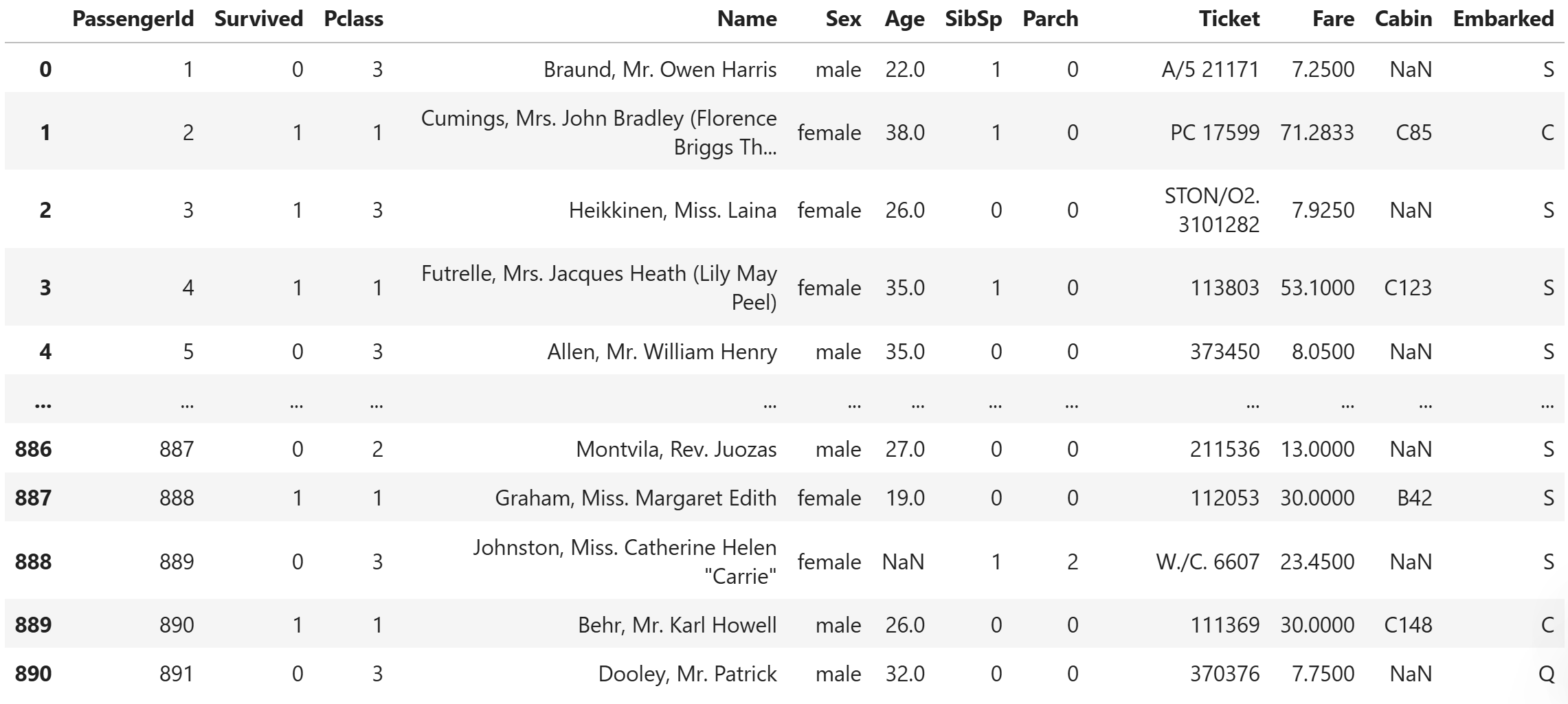
dat.info()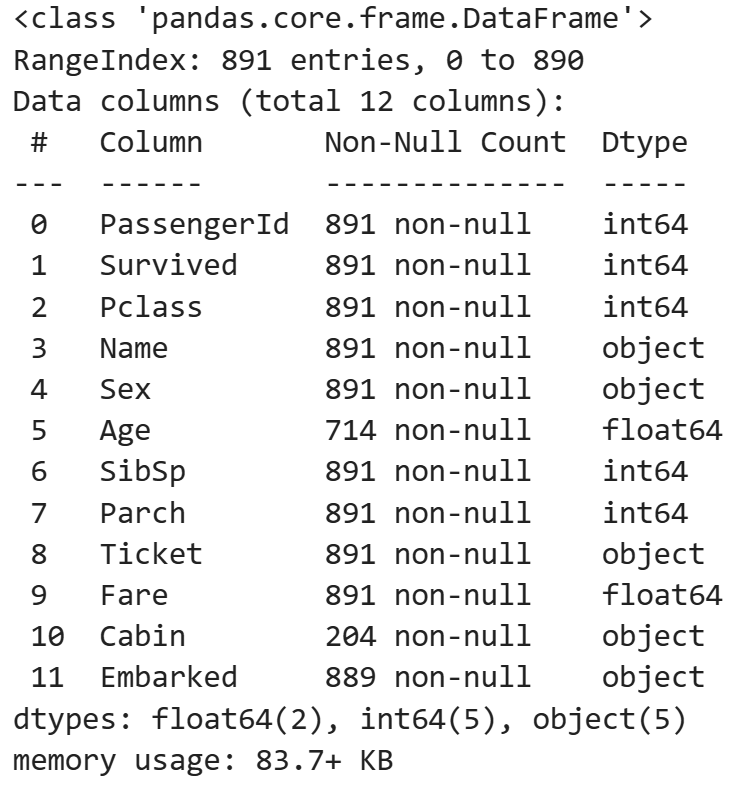
X = dat[ ['Pclass' , 'SibSp'] ]
y = dat['Survived']데이터 선택 및 나누기
- test_size : 테스트 데이터 셋 비율 선택
- random_state : 데이터을 뽑을 때, 지정된 패턴으로 선택
# 90% : 학습용, 10% : 테스트용
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.1,
random_state=0)
X_train.shape, X_test.shape, y_train.shape, y_test.shape결과)
((801, 2), (90, 2), (801,), (90,))
이진 분류, 이항 분류
하이퍼파라미터
튜닝
성능 개선
(pred == y_test).sum() / len(pred)결과)
0.5666666666666667print("테스트 세트의 정확도 : {:.2f}".format(np.mean(pred == y_test)))결과)
테스트 세트의 정확도 : 0.57모델 쓰기 전 데이터 전처리
레이블 인코딩은 문자열로 된 범주형 값을 숫자형 카테고리 값으로 변환하는 방법입니다. 인코딩은 데이터를 특정한 형식으로 변환하여 저장하거나 전송하는 과정이며, 디코딩은 이를 원래의 형태로 복원하는 과정입니다. 디코딩은 인코딩의 반대 개념으로, 데이터의 접근성을 높이기 위해 사용됩니다.
dat.info()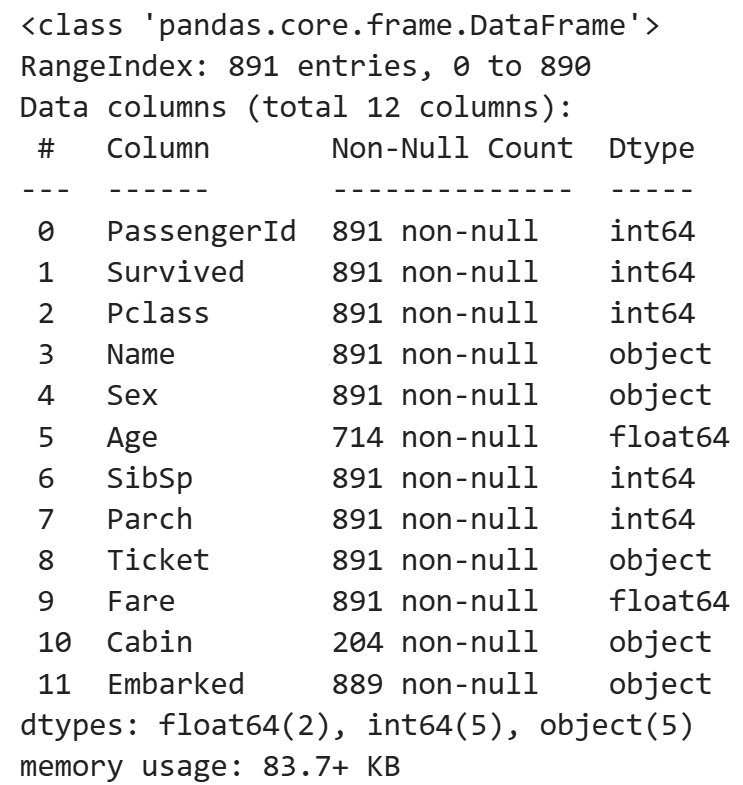
결측치 처리 및 레이블 인코딩
dat.head()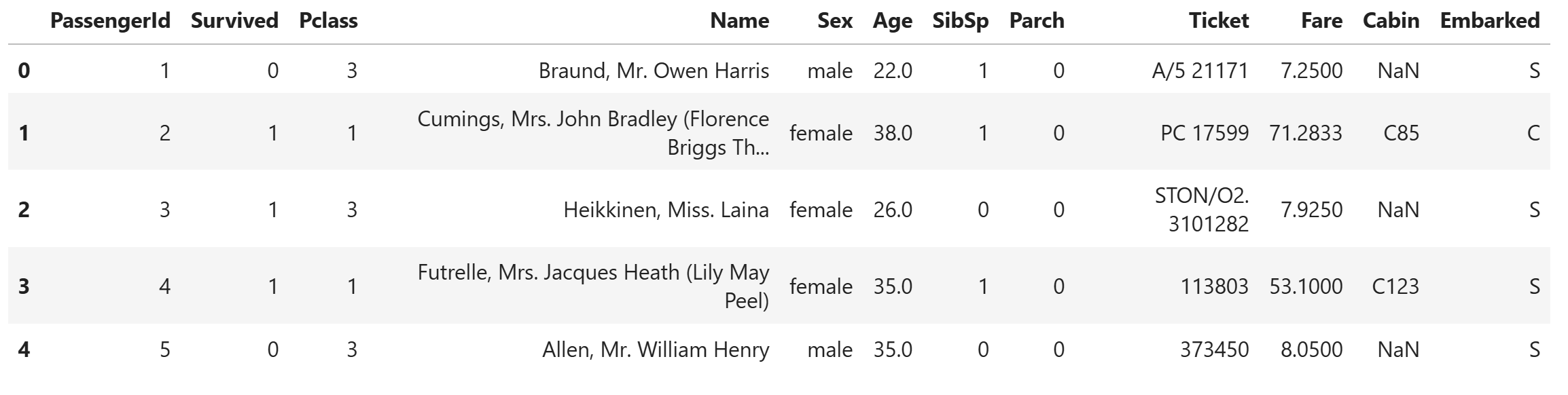
map함수
- [Series].map(함수 또는 변경값) : Series를 대상으로 원하는 함수 적용 또는 값을 대체
- 값으로 dict, Series를 대상으로 한다.
- https://pandas.pydata.org/docs/reference/api/pandas.Series.map.html
mapping = { "male":1, 'female':2 }
dat['Sex_num'] = dat['Sex'].map(mapping)
dat.head()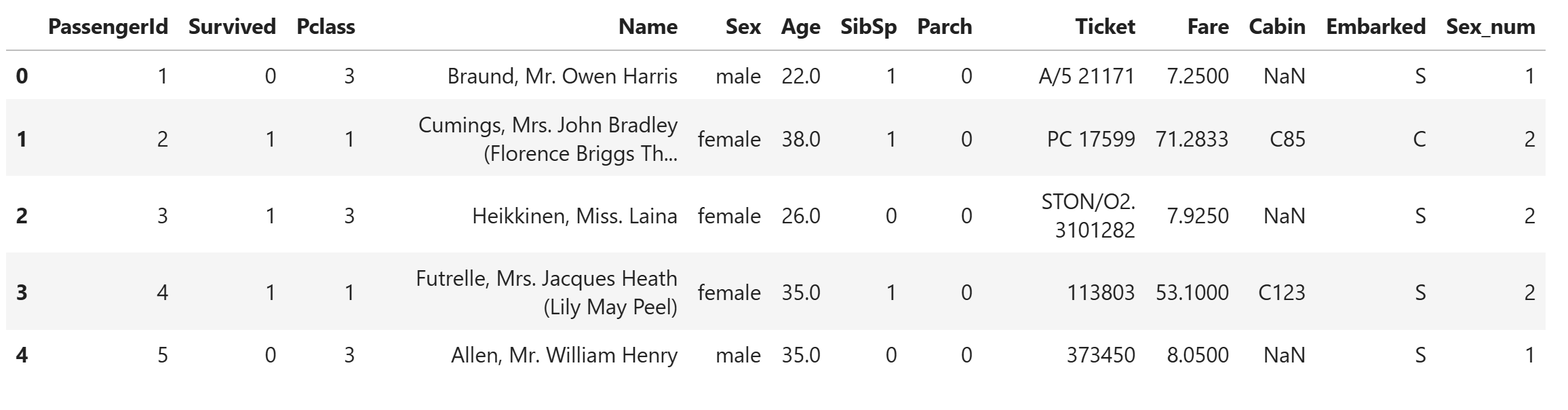
# [].fillna( ) : 결측값을 채운다.
val_mean = dat['Age'].mean()
dat['Age'] = dat['Age'].fillna( val_mean )
dat.info()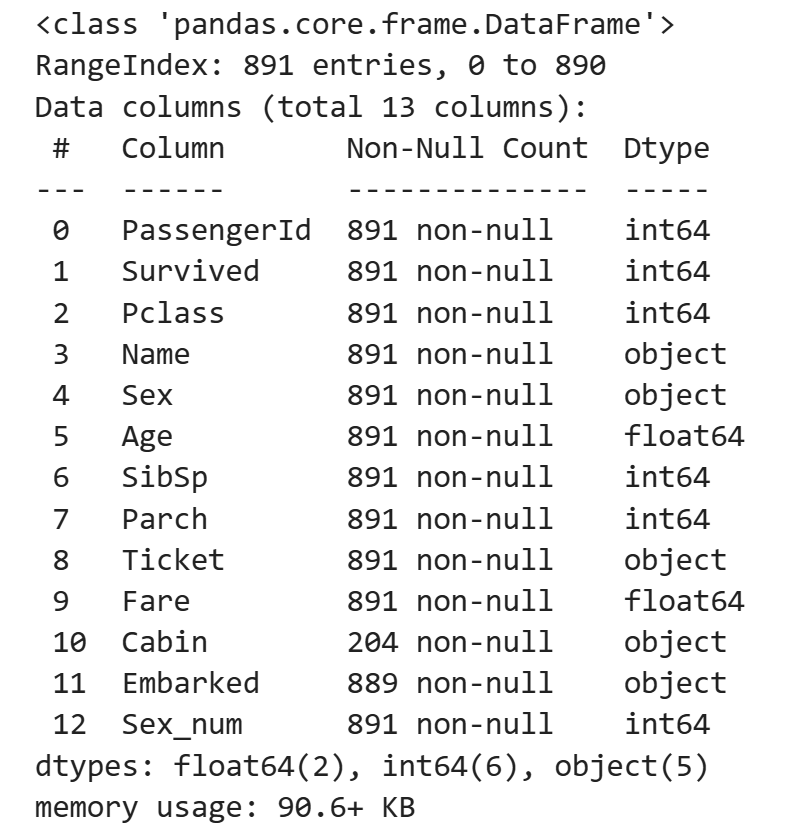
학습, 테스트 데이터 셋 나누기
X = dat[ ['Pclass' , 'SibSp', 'Sex_num', 'Age'] ]
y = dat['Survived']
# 90% : 학습용, 10% : 테스트용
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.1,
random_state=0)
X_train.shape, X_test.shape, y_train.shape, y_test.shape결과)
((801, 4), (90, 4), (801,), (90,))from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=2)
model.fit(X_train, y_train)
### 예측시키기
pred = model.predict(X_test)
print("테스트 세트의 정확도 : {:.2f}".format(np.mean(pred == y_test)))결과)
테스트 세트의 정확도 : 0.76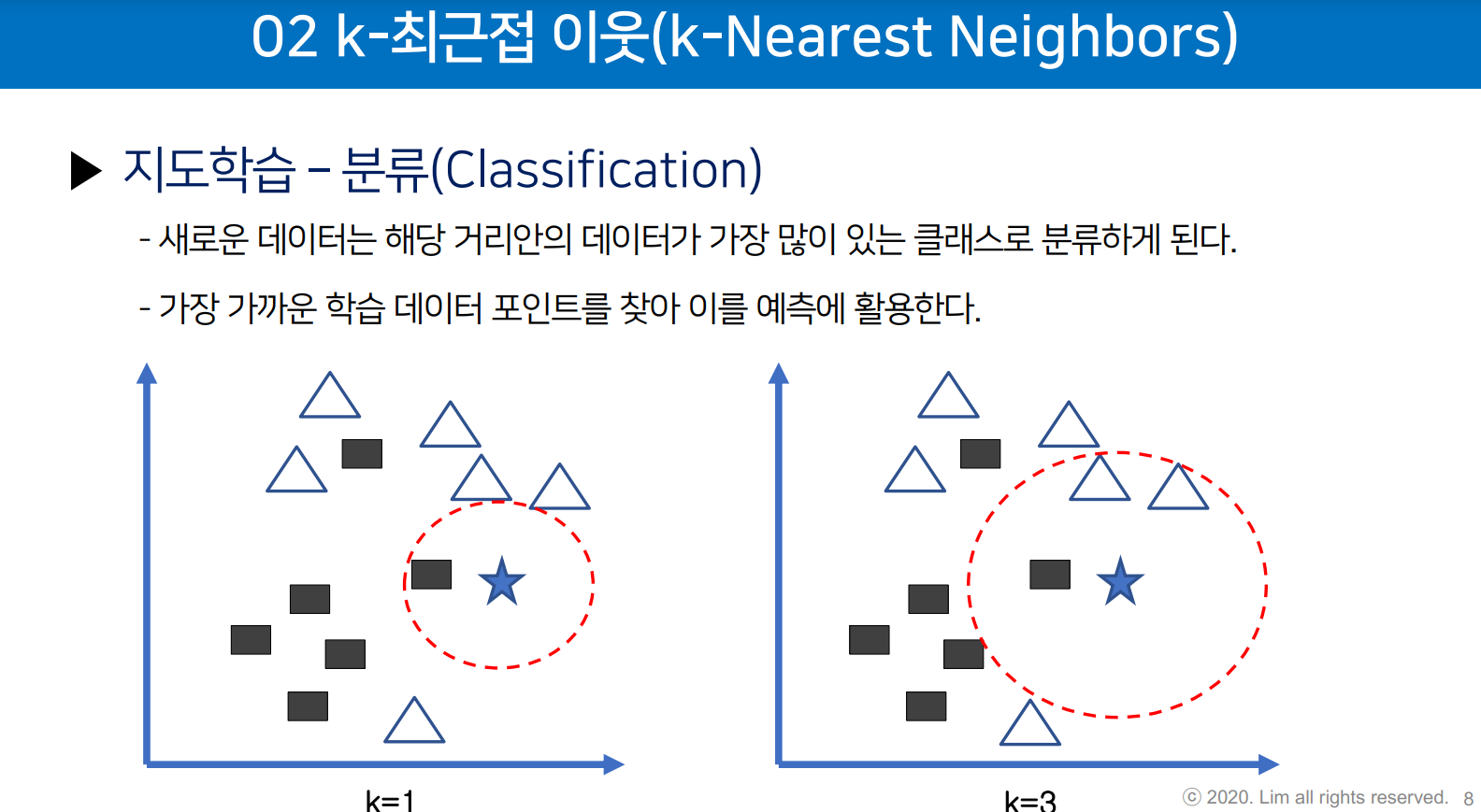
KNN 회귀(K-최근접 이웃 회귀) 모델은 가장 가까운 K개의 이웃 샘플을 이용해 연속적인 값을 예측하는 알고리즘입니다. KNN 분류와 유사한 원리로 작동하지만, 예측하고자 하는 값이 이산적인 것이 아니라 연속적일 때 사용됩니다. 예를 들어, 주어진 입력 샘플의 K개의 가장 가까운 이웃의 평균값을 계산하여 예측 결과를 도출할 수 있습니다.
홀수로 정한다
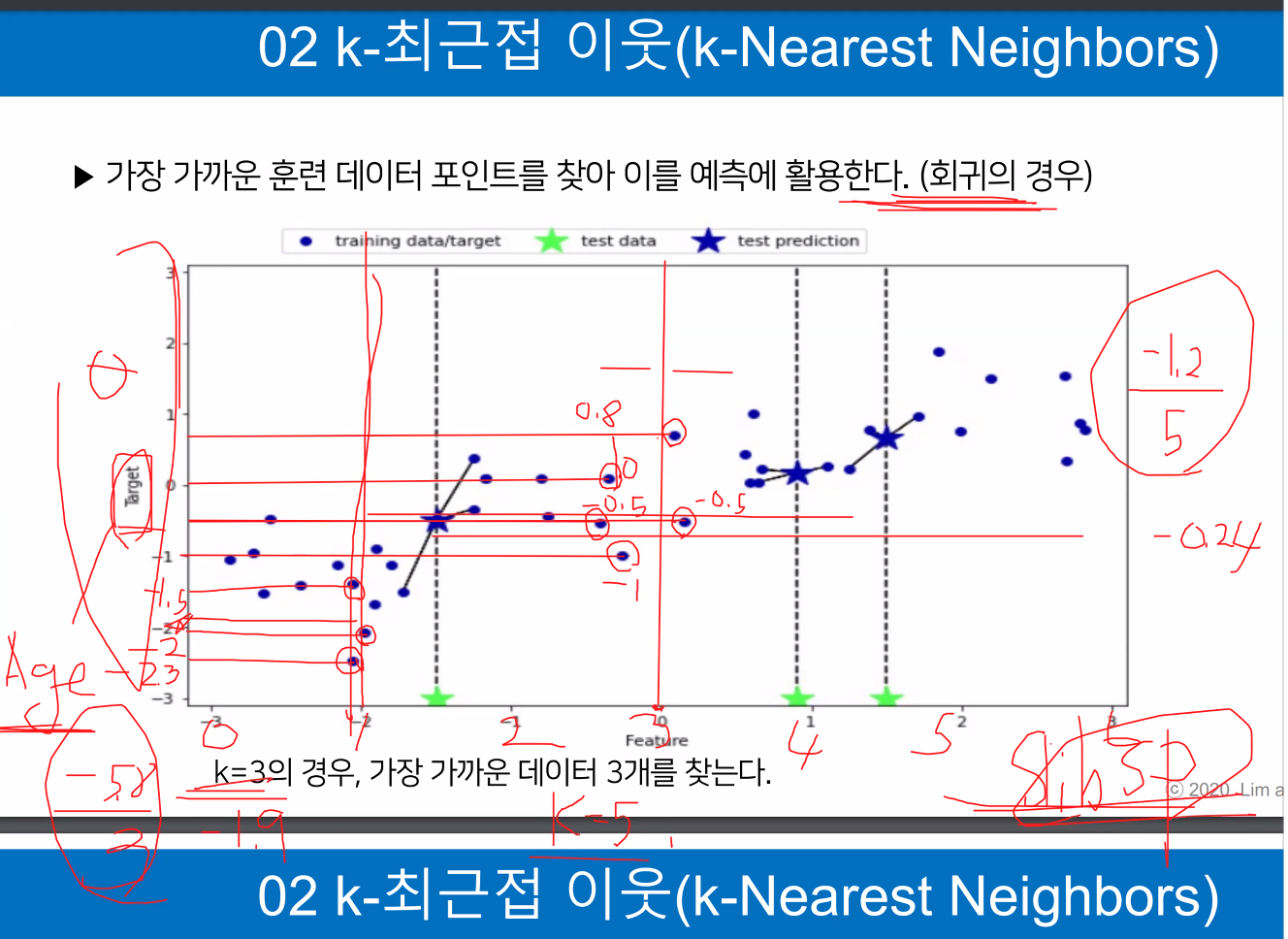
3차원도 가능
tr_acc = []
test_acc = []
k_nums = range(1, 22, 2)# 1,3,5~21
for n in k_nums:
# 모델 선택 및 학습
model = KNeighborsClassifier(n_neighbors=n)
model.fit(X_train, y_train)
# 정확도 구하기
acc_tr = model.score(X_train, y_train)
acc_test = model.score(X_test, y_test)
# 정확도 값 저장.
tr_acc.append(acc_tr)
test_acc.append(acc_test)
print("k : ", n)
print("학습용셋 정확도 {:.3f}".format(acc_tr) )
print("테스트용셋 정확도 {:.3f}".format(acc_test) )결과)
k : 1
학습용셋 정확도 0.878
테스트용셋 정확도 0.733
k : 3
학습용셋 정확도 0.850
테스트용셋 정확도 0.744
k : 5
학습용셋 정확도 0.846
테스트용셋 정확도 0.756
k : 7
학습용셋 정확도 0.821
테스트용셋 정확도 0.733
k : 9
학습용셋 정확도 0.821
테스트용셋 정확도 0.722
k : 11
학습용셋 정확도 0.831
테스트용셋 정확도 0.733
k : 13
학습용셋 정확도 0.811
테스트용셋 정확도 0.767
k : 15
학습용셋 정확도 0.803
테스트용셋 정확도 0.744
k : 17
학습용셋 정확도 0.805
테스트용셋 정확도 0.767
k : 19
학습용셋 정확도 0.785
테스트용셋 정확도 0.711
k : 21
학습용셋 정확도 0.787
테스트용셋 정확도 0.744https://colab.research.google.com/drive/1a4i2igOdXeMqh5U1aBbuI7_istHlzeX6#scrollTo=Y4jzbDfKJiR_
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com
https://heytech.tistory.com/362
[Deep Learning] 평균제곱오차(MSE) 개념 및 특징
📌 Text 빅데이터분석 플랫폼 베타테스트 참가자 모집 중!(네이버페이 4만 원 전원 지급) 👋 안녕하세요, 코딩이 필요 없는 AI/빅데이터 분석 All in One 플랫폼 개발팀입니다.😊 저희
heytech.tistory.com
!pip install graphviz!pip install mglearn # Install the mglearn library
import matplotlib.pyplot as plt
import mglearnplt.figure(figsize=(10,10))
mglearn.plots.plot_animal_tree()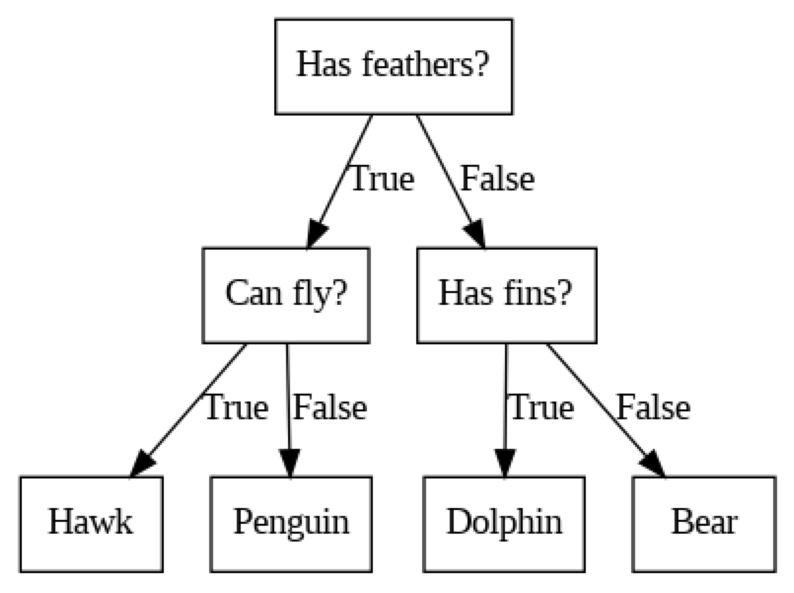
- (가) 트리에 사용되는 세 개의 feature가 있음.
- 'Has feathers?'(날개가 있나요?)
- 'Can fly?'(날수 있나요?)
- 'Has fins?'(지느러미가 있나요?)
- (나) 이 머신러닝 문제는 네 개의 클래스로 구분하는 모델을 생성
- 네 개의 클래스 - 매, 펭권, 돌고래, 곰
- (다) 노드 종류
- 맨 위의 노드 - Root Node(루트 노드)
- 맨 마지막 노드 - Leaf Node(리프 노드)
- target가 하나로만 이루어진 Leaf Node(리프 노드) 순수 노드 (pure node)
- 자식 노드가 없는 최하위의 노드를 리프 노드(Leaf node : 잎)라고 하고, 리프 노드가 아닌 자식 노드를 가지고 있는 노드를 내부 노드(Internal node)라고 한다. 리프 노드 중에서도 하나의 타겟 값만을 가지는 노드를 순수 노드(Pure node)라고 한다.
- 리프 노드(Leaf Node)는 결정 트리에서 최하위 노드를 의미하며, 중단 없이 데이터를 분류한 최종 결과를 나타냅니다. 순수 노드(Pure Node)는 리프 노드 중에서 하나의 클래스(타깃 값)만을 가지는 노드를 지칭합니다. 즉, 순수 노드는 해당 노드에 포함된 데이터들이 모두 동일한 클래스로 분류되는 경우입니다.
- (라) 노드 분기(각 노드)
- 범주형은 데이터를 구분하는 질문 을 통해 나눈다.
- 연속형은 특성 i가 a보다 큰가?의 질문으로 나눈다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
import seaborn as snscancer = load_breast_cancer()
X = cancer.data
y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y,
stratify=cancer.target,
test_size = 0.3,
random_state=77)tree = DecisionTreeClassifier(max_depth=2, random_state=0)
tree.fit(X_train, y_train)
print("훈련 세트 정확도 : {:.3f}".format(tree.score(X_train, y_train)))
print("테스트 세트 정확도 : {:.3f}".format(tree.score(X_test, y_test)))결과)
훈련 세트 정확도 : 0.972
테스트 세트 정확도 : 0.912for i in range(1,7,1):
tree = DecisionTreeClassifier(max_depth=i, random_state=0)
tree.fit(X_train, y_train)
print(f"max_depth : {i}")
print("훈련 세트 정확도 : {:.3f}".format(tree.score(X_train, y_train)))
print("테스트 세트 정확도 : {:.3f}".format(tree.score(X_test, y_test)))결과)
max_depth : 1
훈련 세트 정확도 : 0.932
테스트 세트 정확도 : 0.883
max_depth : 2
훈련 세트 정확도 : 0.972
테스트 세트 정확도 : 0.912
max_depth : 3
훈련 세트 정확도 : 0.982
테스트 세트 정확도 : 0.906
max_depth : 4
훈련 세트 정확도 : 0.985
테스트 세트 정확도 : 0.906
max_depth : 5
훈련 세트 정확도 : 0.992
테스트 세트 정확도 : 0.889
max_depth : 6
훈련 세트 정확도 : 0.997
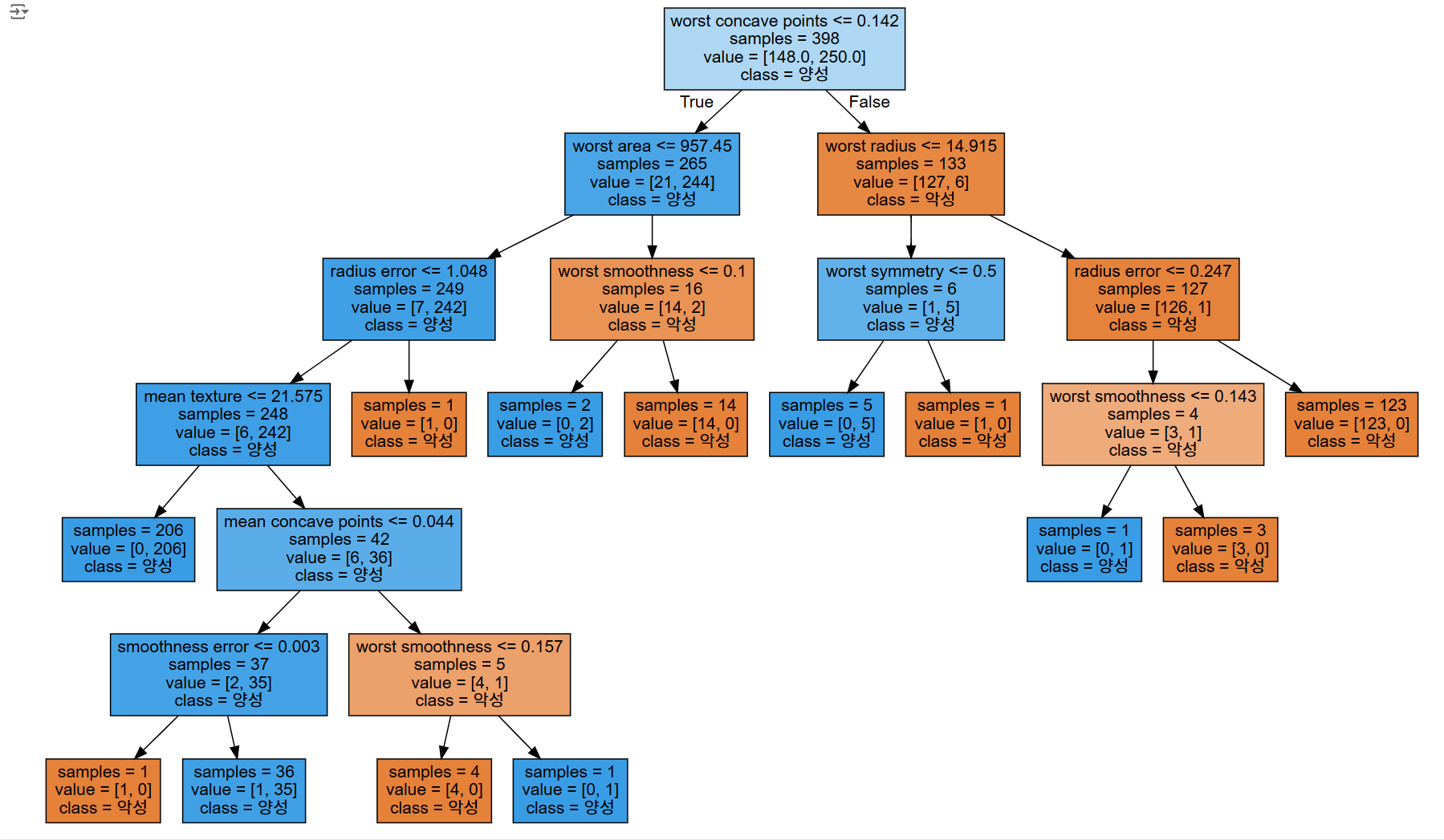
테스트 세트 정확도 : 0.901from sklearn.tree import export_graphviz
import graphvizexport_graphviz(tree,
out_file="tree.dot",
class_names=['악성', '양성'],
feature_names = cancer.feature_names,
impurity = False, # gini 계수
filled=True) # colorwith open("tree.dot") as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))결과)
import torch
# PyTorch 버전 확인
print(torch.__version__)
# CUDA 사용 가능 여부 확인
print(torch.cuda.is_available())
# 사용 가능한 GPU 장치 수 확인
print(torch.cuda.device_count())결과)
2.5.0+cu121
True
1https://ldjwj.github.io/DL_Basic/part04_01_dl_start/ch01_03_NNet_Titanic_pytorch_V01_2411.html
ch01_03_NNet_Titanic_pytorch_V01_2411
ldjwj.github.io
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputerimport pandas as pd # import pandas and assign it to the alias pd # NumPy 라이브러리를 임포트하고 np로 별칭을 지정합니다.
# 시드 고정
torch.manual_seed(42)
np.random.seed(42)
# 1. 데이터 준비
# 데이터 로드
data = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
data.shape결과)
(891, 12)# 필요한 피처 선택
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']
target = 'Survived'
# 성별 인코딩
data['Sex'] = data['Sex'].map({'male': 0, 'female': 1})
import pandas as pd
from sklearn.impute import SimpleImputer # Import SimpleImputer from sklearn.impute
# 결측값 처리
imputer = SimpleImputer(strategy='median')
X = imputer.fit_transform(data[features])
y = data[target].values# 결측값이 처리되었는지 확인
print("결측값 처리 후 데이터:")
print(pd.DataFrame(X, columns=features).isnull().sum())결과)
결측값 처리 후 데이터:
Pclass 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
dtype: int64# Import StandardScaler from sklearn.preprocessing
# from sklearn.preprocessing import Standard
from sklearn.preprocessing import StandardScaler # Changed 'Standard' to 'StandardScaler'
# 스케일링
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# NumPy to PyTorch Tensor 변환
# X_train이라는 NumPy 배열을 PyTorch의 FloatTensor로 변환.
# FloatTensor는 32비트 부동 소수점 숫자로 구성된 텐서를 생성.
# 이 변환은 PyTorch 모델에서 데이터를 처리할 수 있도록 준비하는 단계
X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.FloatTensor(y_train).unsqueeze(1)
y_test = torch.FloatTensor(y_test).unsqueeze(1)# 2. 신경망 모델 정의
model = nn.Sequential(
nn.Linear(6, 16),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(16, 8),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(8, 1),
nn.Sigmoid()
)# 3. 모델 학습
# 손실 함수와 옵티마이저 정의
criterion = nn.BCELoss() # 이진 분류 손실 함수
optimizer = optim.Adam(model.parameters(), lr=0.001)# 학습 진행
epochs = 100
for epoch in range(epochs):
# 순전파
outputs = model(X_train)
loss = criterion(outputs, y_train)
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 20번마다 손실 출력
if (epoch + 1) % 20 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')결과)
Epoch [20/100], Loss: 0.7141
Epoch [40/100], Loss: 0.7019
Epoch [60/100], Loss: 0.6749
Epoch [80/100], Loss: 0.6433
Epoch [100/100], Loss: 0.5905# 4. 모델 평가
model.eval() # 평가 모드
with torch.no_grad():
test_outputs = model(X_test)
predicted = (test_outputs > 0.5).float()
accuracy = (predicted == y_test).float().mean()
print(f'Test Accuracy: {accuracy.item():.4f}')결과)
Test Accuracy: 0.7877https://snaiws.notion.site/DL-with-logit-a857e414f2ed4dfab2c51ad738388d84
DL with logit | Notion
학습(learning)
snaiws.notion.site



